GMV Forecasting via xDeepFM
In this post, I aim to share how I conducted a proof of concept (PoC) to solve a real-world problem using deep learning techniques, emphasizing a clean code structure.
Background
Our initiative is centered on forecasting Gross Merchandise Volume (GMV) through sophisticated machine learning models. Crafted to navigate the complexities of real-world data scenarios, including cold starts, sparse signals, and voluminous datasets, our forecasting system is equipped with a suite of solutions engineered to methodically overcome these challenges.
Note: As the original data is confidential, we won’t disclose any data sources.
For further details, please refer to the GitHub repository.
Exploratory Data Analysis
We will share the findings and feature engineering derived from three primary data sources: user, store, and transaction data.
Findings:
- User Behavior Variability: There is a noticeable fluctuation in user behaviors when observed over various time frames, such as hourly or monthly.
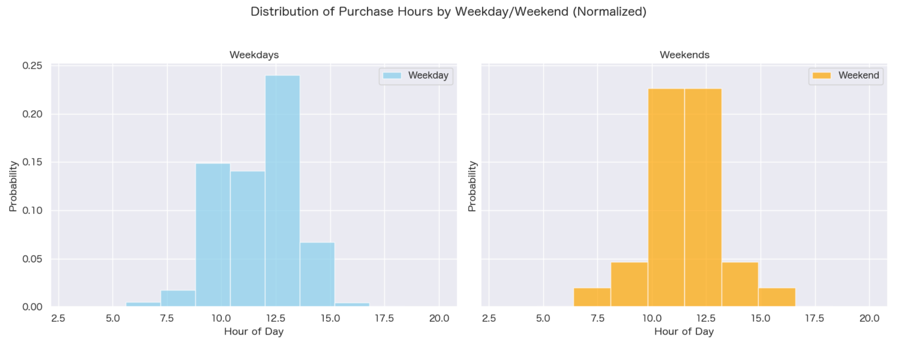
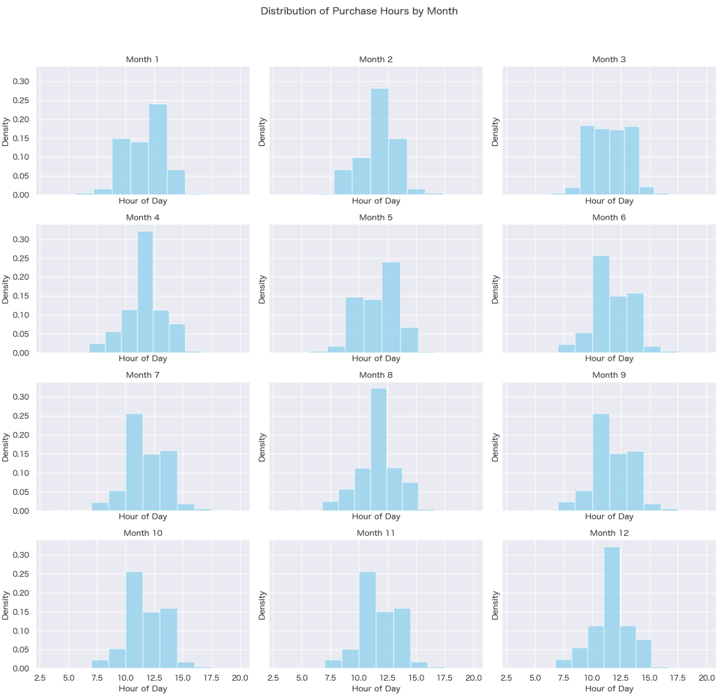
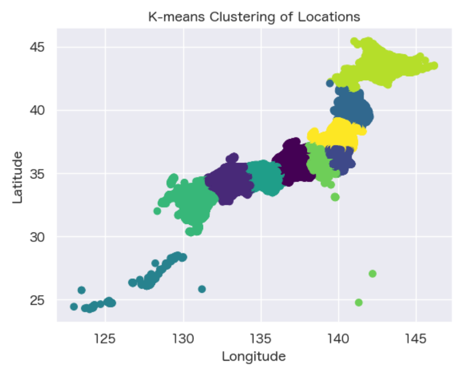
- Spatial Relationship Analysis: K-means clustering has been applied to categorize spatial locations, effectively preserving their inherent spatial relationships.
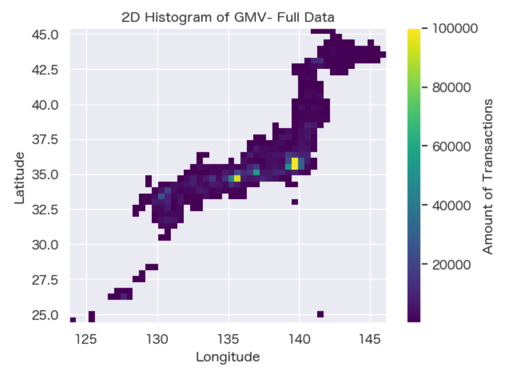
- Context Feature Exploration: The RMF (Recency, Frequency, Monetary) analysis method has been utilized to pinpoint key context features that are significant.
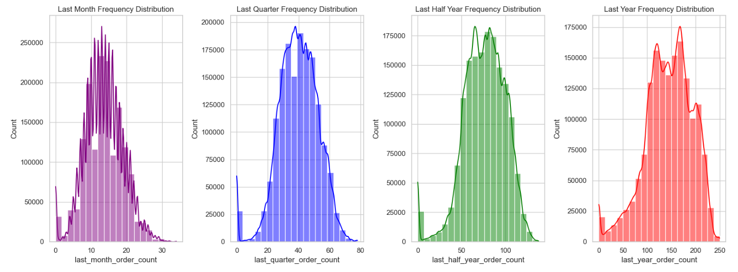
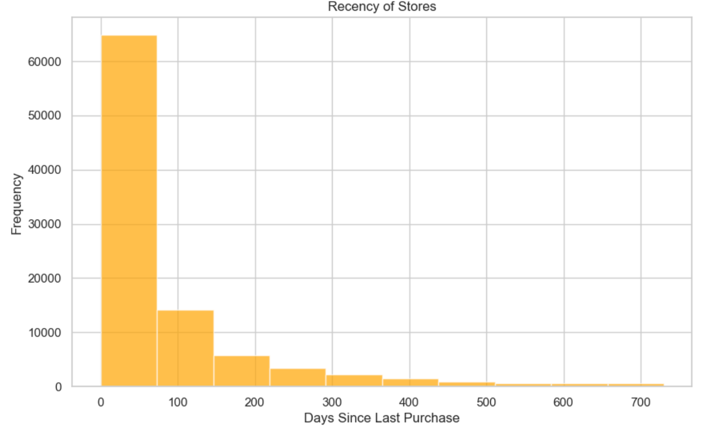
- For a comprehensive examination, please consult the exploratory data analysis notebook provided in the documentation - exploratory data analysis notebook.
Feature Engineering:
-
Missing Value Imputation: For simplicity, apply median imputation to fill missing values in numeric features, and mode imputation for categorical features to maintain data integrity.
-
Context Feature Creation: Develop new context features derived from insights gathered during exploratory data analysis, enhancing model input.
-
Binarization of Continuous Features: Convert continuous features into binary form using summary statistics thresholds to streamline the xDeepFM model training process.
Methodology
The forecasting of GMV is approached through two steps:
-
Predicting Purchase Probability: Utilize a Click-Through Rate (CTR) model to predict the likelihood of a user completing a purchase at a given store in the subsequent period.
-
Estimating GMV: Use the predicted purchase probability in conjunction with the store’s average GMV to forecast the forthcoming GMV for a user or a specific day.
Problem Transformation
Transform the Forecast GMV time series in terms of users or daily sum by the following three steps:
- Estimate the probability of user purchase at a store on a daily basis: For each user, build a binary classification (CTR-like) model to predict the probability of the user placing an order at each store in January 2022. Let’s denote this probability as \(P(\text{Order}_{\text{user, store}}| \text{date})\).
- For forecasting, use the trained model to predict \(P(\text{Order}_{\text{user, store}}| \text{date})\) for each user and store.
- Calculate the expected GMV for each user by taking the weighted average of the GMV amounts at the predicted stores:
\(\hat{\text{GMV}}_{\text{user}, \text{date}} = \sum_{\text{store}} \hat{P}(\text{Order}_{\text{user, store}}| \text{features}_\text{date}) \cdot \hat{\text{GMV}}_{\text{store}}\)
- We assume $\hat{\text{GMV}}_{\text{store}}$ can be estimated by averaging their previous transactions due to low variation (based on exploratory data analysis). Alternatively, it can be estimated using another ML algorithm.
- Context features $\text{features}_\text{date}$ can be updated over time.
- Main Forecast Problems:
- User-Level Forecast in a Month:
- For forecasting user’s monthly GMV, aggregate the expected GMV amounts across all users.
- Mathematically: \(\text{GMV}(\text{user}) = \sum_{\text{date}} \hat{\text{GMV}}_{\text{user}, \text{date}}\) where the sum is over all users.
- Daily Forecast in a Month:
- For forecasting daily GMV, aggregate the expected GMV amounts across all users.
- Mathematically: \(\text{GMV}(\text{date}) = \sum_{\text{user}} \hat{\text{GMV}}_{\text{user}, \text{date}}\) where the sum is over all users.
- User-Level Forecast in a Month:
Data Setup:
- Label Definition:
- The label is binary information indicating whether the user placed an order at a specific store in January 2022.
- Use negative sampling for negative examples with a globally random sampling strategy.
- Features:
- Utilize historical data features for each user and store, such as previous order history, user demographics, store characteristics, etc.
- Include context features, especially those describing the future time context for prediction.
Evaluation:
- Assess the performance of CTR-like model using standard binary classification metrics (recall, ROC-AUC, etc.).
- Evaluate the performance of GMV estimation using appropriate regression metrics (MAE, MSE, etc.).
This approach leverages the predicted probabilities to estimate the expected GMV for each user and store, aggregating these estimates as a whole. Adjust the model complexity and features based on the characteristics of data and business requirements.
Model Training
Training Model: Extreme DeepFM (xDeepFM)
The Extreme DeepFM (xDeepFM) model is an advanced neural network designed for click-through rate prediction and recommendation systems. It enhances the standard DeepFM framework by integrating a Compressed Interaction Network (CIN) layer, enabling the model to capture complex feature interactions at a higher order with greater efficacy.
Key Components:
-
Embedding Layer: Transforms categorical features into dense vectors, enabling nuanced feature interactions.
-
Deep Component: Comprises several fully connected layers that learn intricate data patterns.
-
Compressed Interaction Network (CIN): Efficiently computes feature interactions across layers, ideal for handling large datasets.
Training Process:
-
Sampling: Trains on both positive (real transactions) and negative (randomly sampled) labels to differentiate between outcomes.
-
Loss Function: Employs binary cross-entropy loss to quantify the difference between predicted probabilities and actual labels.
-
Training Data Generation:
- Implement a strategy to redefine unseen users/stores during model validation and testing to prevent data leakage.
- Utilize a leave-one experiment approach for creating train/validation/test datasets, e.g.,
- Test: Current month
- Valid: One month earlier than the test month
- Train: One month earlier than the validation month
Architecture Overview:
The architecture diagram of xDeepFM illustrates the intricate design of the model, showcasing the embedding layers, deep network components, and the innovative CIN layer for advanced feature interaction learning.
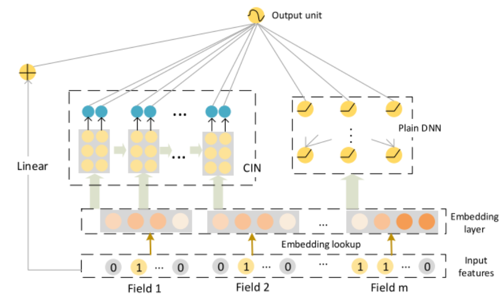
Advantages of xDeepFM:
- Complex Feature Learning: The CIN layer in xDeepFM intricately learns feature interactions, enhancing prediction accuracy.
- Large-Scale Data Handling: Its efficient computation makes xDeepFM ideal for processing extensive datasets.
- Versatile Application:: The model’s flexible design adapts to various domains, including recommendation systems and digital marketing.
The xDeepFM model’s sophisticated capabilities enable it to grasp the nuanced dynamics between users and stores, refining GMV forecast precision.
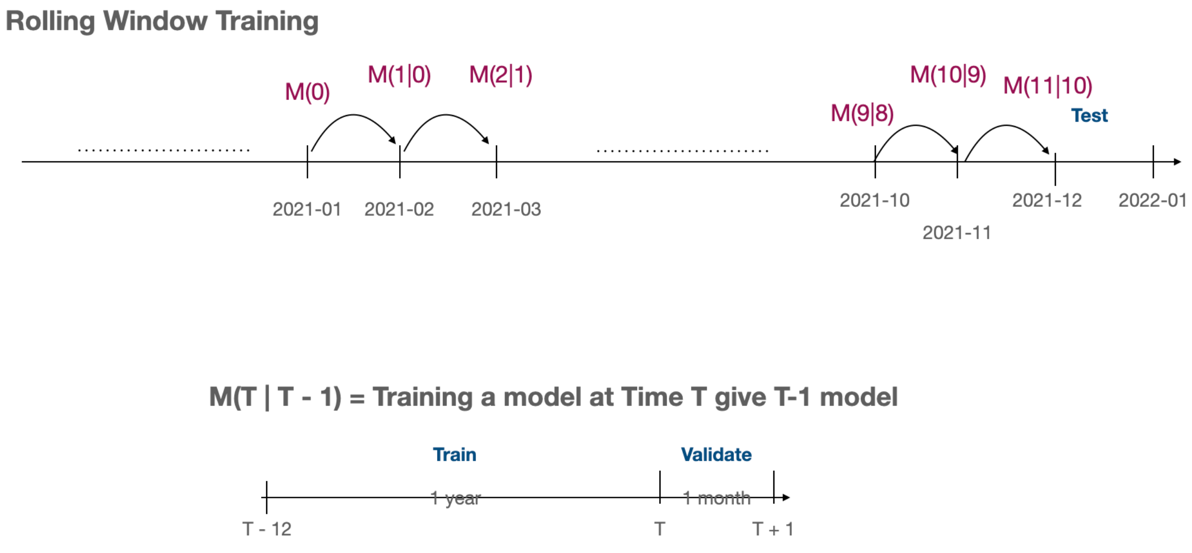
Training Strategy: Rolling Window
- Temporal Dynamics: A rolling window strategy captures time-dependent patterns, addressing autocorrelation concerns.
- Dynamic Adaptation: Regular updates to the training data ensure the model stays attuned to evolving data trends.
- Informed Predictions: Historical data within each window informs the model, bolstering prediction reliability.
- Feature Enrichment: Rolling windows compute RFM-like metrics, offering additional data insights.
For visual representation, please include the rolling window figure in the final documentation as referenced.
Training Validation
During a typical training month, the AUC score averages around 0.84. There is room for enhancement through careful hyperparameter optimization.

Forecast
Workflow
- The process from the
start_dateto theend_dateinvolves the following steps:- Embedding Utilization: Leverage user and store embeddings, adjusted for various dates, in conjunction with context embeddings from the trained model.
- Top-1 Store Prediction by FAISS: Use FAISS to pinpoint the store where a user is most likely to transact, informed by EDA insights.
- GMV Estimation: Calculate the expected daily user GMV using the established formula.
- Afterward, synthesize the findings to present a dual perspective: individual user behavior and daily aggregate trends.
Results
- Time-series comparison
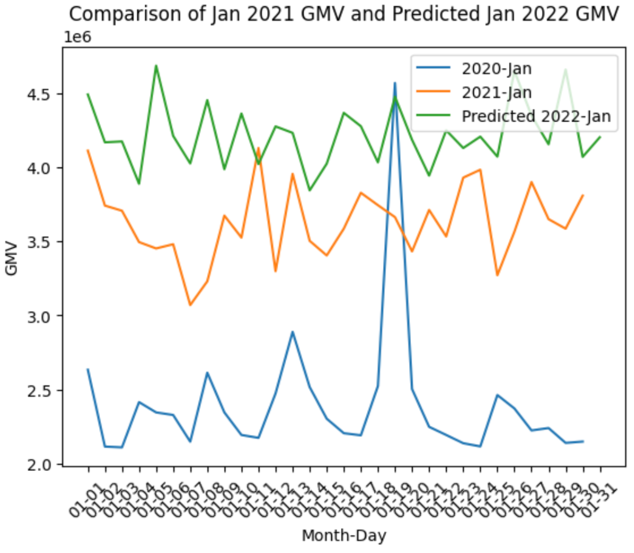
- Visualizations and further analysis can be found in the (notebook)[notebooks/forecast_analysis.ipynb]. F
- While the evaluation process may be simplified for this challenge, the necessary evaluation functions are prepared for integration within
forecaster/evaluation/. - It is recommended to assess the mean-squared errors of the GMV forecasts to gain a deeper understanding of the model’s performance.
Engineering Aspects
High-Level Flow
In this real-world case, the architecture of the forecaster is depicted in the provided diagram, illustrating the system’s workflow and component interaction.
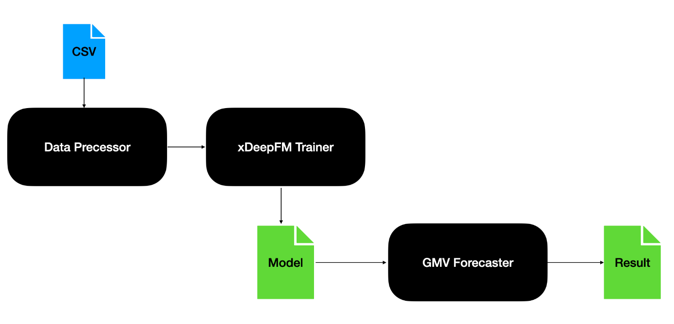
- Note that we can easily change the csv files as other data sources e.g., Hive/HBase by adding more handlers in
forecaster/data/
Result Reproducible
To replicate the forecasting results, adhere to the following procedure:
- Prerequisite: Confirm the installation of Miniconda is installed.
- Environment Setup: Use the command for environment preparation.
make install - Model Training: Initiate rolling-window model training with
- Default
make train - Custom data path:
source activate forecaster python forecaster/run_training.py \ --user_data_path "{user_data_path}" \ --transaction_data_path "{transaction_data_path}" \ --store_data_path "{transaction_data_path}"
- Default
- GMV Forecasting: Generate GMV forecasts by running
- Default:
make forecast - Custom data path and predicted date range:
source activate forecaster python forecaster/run_forecasting.py \ --user_data_path "{user_data_path}" \ --transaction_data_path "{transaction_data_path}" \ --store_data_path "{transaction_data_path}" \ --start_date "{yyyymmdd}" \ --end_date "{yyyymmdd}"
- Default:
Reference
- J Lian, et al. xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems, 2018.
- https://github.com/egpivo/gmv-forecaster/tree/main