How I'm Building a Context-Aware Retriever to Boost RAG Quality (Part 2: Implementation)
In Part 1, I walked through the design. Now let’s see it in action with a hands-on example using the ContractNLI dataset. I’ll assume chunking is already handled upstream.
High-level flow
The implementation follows the pipeline from Part 1:
- File discovery: semantic retrieval with optional file-level reranking to identify the most relevant documents.
- Multi-variant chunk search: per-file parallel search using the original query plus LLM-generated boosted variants.
- Answer extraction: clause-aware formatting that preserves exact wording for legal text or produces structured comparisons across files.
- Reflection (optional): quality assessment to validate grounding, completeness, and consistency.
MCP tools and DSPy
The system is built on FastMCP and uses DSPy for structured prompting. The MCP server exposes a few tools—file_discover, assistant, and a handful of utilities—that can be called directly or wired into orchestration platforms like Dify or n8n.

MCP server setup
The entry point is straightforward. The assistant tool coordinates the entire pipeline:
from fastmcp import FastMCP
mcp = FastMCP("kb-mcp-server")
@mcp.tool()
async def assistant(
query: str,
dataset_info: str,
custom_instructions: str = None,
document_name: str = None,
enable_query_rewriting: bool = False
) -> Dict[str, Any]:
"""
Context-aware retrieval for knowledge base questions.
Orchestrates: intent detection → file discovery →
chunk search with boosting → answer extraction → reflection
"""
# Initialize services with credentials from headers
services = await initialize_services()
# Stage 1: Understand query intent and discover files
discovery = await services.discovery.find_files(
query=query,
dataset_info=dataset_info,
enable_rewriting=enable_query_rewriting
)
# Stage 2: Search chunks with boosted queries
chunks = await services.search.find_chunks(
query=query,
files=discovery["files"],
domain=discovery["domain"],
custom_instructions=custom_instructions
)
# Stage 3: Extract and format answer
answer = await services.aggregator.build_answer(
chunks=chunks,
intent=discovery["intent"],
query=query
)
# Stage 4 (optional): Reflect on answer quality
if services.reflection_enabled:
answer = await services.reflector.validate(answer, query)
return answer
Key moving parts:
- Header-based auth: credentials for retrieval, LLM, and reranking services are passed via HTTP headers (
X-RETRIEVAL-ENDPOINT,X-RETRIEVAL-API-KEY,X-LLM-API-URL,X-LLM-MODEL, etc.), so you can swap backends without touching code. - Service initialization: each stage (discovery, search, aggregation, reflection) is a separate service that can be configured independently.
- Async design: everything runs asynchronously to maximize parallelism across files and query variants.
DSPy for structured prompting
Each service uses DSPy signatures to define its inputs and outputs. Here’s how intent detection and content boosting work:
import dspy
class QueryIntentSignature(dspy.Signature):
"""Detect the intent and domain of a user query."""
query = dspy.InputField(desc="User's search query")
intent_type = dspy.OutputField(desc="Intent: clause_lookup, comparison, or general")
domain = dspy.OutputField(desc="Domain: legal, healthcare, business, etc.")
key_entities = dspy.OutputField(desc="List of key entities to search for")
class FileDiscoveryService:
def __init__(self):
self.intent_detector = dspy.ChainOfThought(QueryIntentSignature)
async def find_files(self, query: str, dataset_info: str):
# Use DSPy to understand intent
intent = self.intent_detector(query=query)
# Run semantic search + optional reranking
files = await self._search_files(query, intent.key_entities)
return {
"files": files,
"intent": intent.intent_type,
"domain": intent.domain
}
For content boosting, we generate domain-specific keywords per file:
class ContentBoostSignature(dspy.Signature):
"""Generate complementary keywords for content boosting."""
query = dspy.InputField(desc="User's search query")
document_name = dspy.InputField(desc="Target document being searched")
custom_instructions = dspy.InputField(desc="Domain-specific guidance")
keyword_sets = dspy.OutputField(desc="Array of keyword arrays for boosting")
class ChunkSearchService:
def __init__(self):
self.content_booster = dspy.ChainOfThought(ContentBoostSignature)
async def find_chunks(self, query: str, files: List[str], domain: str):
tasks = [self._search_with_query(query, files)] # Original query
# Generate boosted queries per file
for file in files[:3]:
boost = self.content_booster(
query=query,
document_name=file,
custom_instructions=f"Focus on {domain} domain"
)
for keywords in boost.keyword_sets:
boosted_query = " ".join(keywords)
tasks.append(self._search_with_query(boosted_query, [file]))
# Run all searches in parallel
results = await asyncio.gather(*tasks)
return self._merge_and_deduplicate(results)
The aggregation service uses different DSPy signatures depending on the intent:
class ClauseLookupSignature(dspy.Signature):
"""Extract specific clauses preserving exact wording."""
context = dspy.InputField(desc="Document chunks")
user_query = dspy.InputField(desc="User's question")
answer = dspy.OutputField(desc="Extracted clauses with verbatim quotes")
citations = dspy.OutputField(desc="Source documents and sections")
class AggregationService:
def __init__(self):
self.clause_extractor = dspy.ChainOfThought(ClauseLookupSignature)
async def build_answer(self, chunks: List[Chunk], intent: str, query: str):
if intent == "clause_lookup":
return self.clause_extractor(
context=self._chunks_to_context(chunks),
user_query=query
)
# ... other intent types
Example on ContractNLI
I loaded the ContractNLI dataset into a Dify knowledge base and ran the retriever both as a standalone service and as part of a Dify agent workflow. Here’s a quick walkthrough.
Calling the tools directly
You can call file_discover and assistant via curl or any HTTP client. Both tools expect the same auth headers (X-RETRIEVAL-ENDPOINT, X-RETRIEVAL-API-KEY, X-LLM-API-URL, X-LLM-MODEL, and optionally X-RERANK-URL and X-RERANK-MODEL).
1. Discover files
curl -s \
-H 'Content-Type: application/json' \
-H 'X-RETRIEVAL-ENDPOINT: https://your-dify-or-backend' \
-H 'X-RETRIEVAL-API-KEY: $YOUR_API_KEY' \
-H 'X-LLM-API-URL: https://api.openai.com/v1' \
-H 'X-LLM-MODEL: gpt-4o' \
'http://localhost:9003/mcp' \
-d '{
"tool": "file_discover",
"parameters": {
"query": "confidentiality after NDA termination at University of Michigan",
"dataset_id": "your-dataset-id",
"top_k_return": 10,
"do_file_rerank": true
}
}'
This returns a ranked list of file names. If you’ve configured a reranker (e.g., Jina), the ranking reflects that.
2. Ask the assistant
curl -s \
-H 'Content-Type: application/json' \
-H 'X-RETRIEVAL-ENDPOINT: https://your-dify-or-backend' \
-H 'X-RETRIEVAL-API-KEY: $YOUR_API_KEY' \
-H 'X-LLM-API-URL: https://api.openai.com/v1' \
-H 'X-LLM-MODEL: gpt-4o' \
'http://localhost:9003/mcp' \
-d '{
"tool": "assistant",
"parameters": {
"dataset_info": "[{\"id\": \"your-dataset-id\", \"source_path\": \"\"}]",
"query": "What confidentiality obligations remain after the NDA expires or is terminated?",
"custom_instructions": "Focus on legal clauses and preserve original wording where critical.",
"enable_query_rewriting": true
}
}'
The assistant orchestrates the full pipeline: intent detection, file discovery, per-file chunk search with boosted queries, answer extraction, and optional reflection. A few notes on parameters:
dataset_infois a JSON string with{id, source_path}pairs—one or more datasets can be queried at once.document_name(not shown here) lets you pin the search to a specific file if you already know the target.enable_query_rewritingexpands or relaxes the query before running intent detection.
Wiring it into a Dify agent
Instead of calling the tools directly, you can configure a Dify workflow to invoke the assistant as a retrieval step. The agent passes the user query and dataset IDs to the MCP server and receives a structured answer with citations. Below is a screenshot of a test run on ContractNLI:
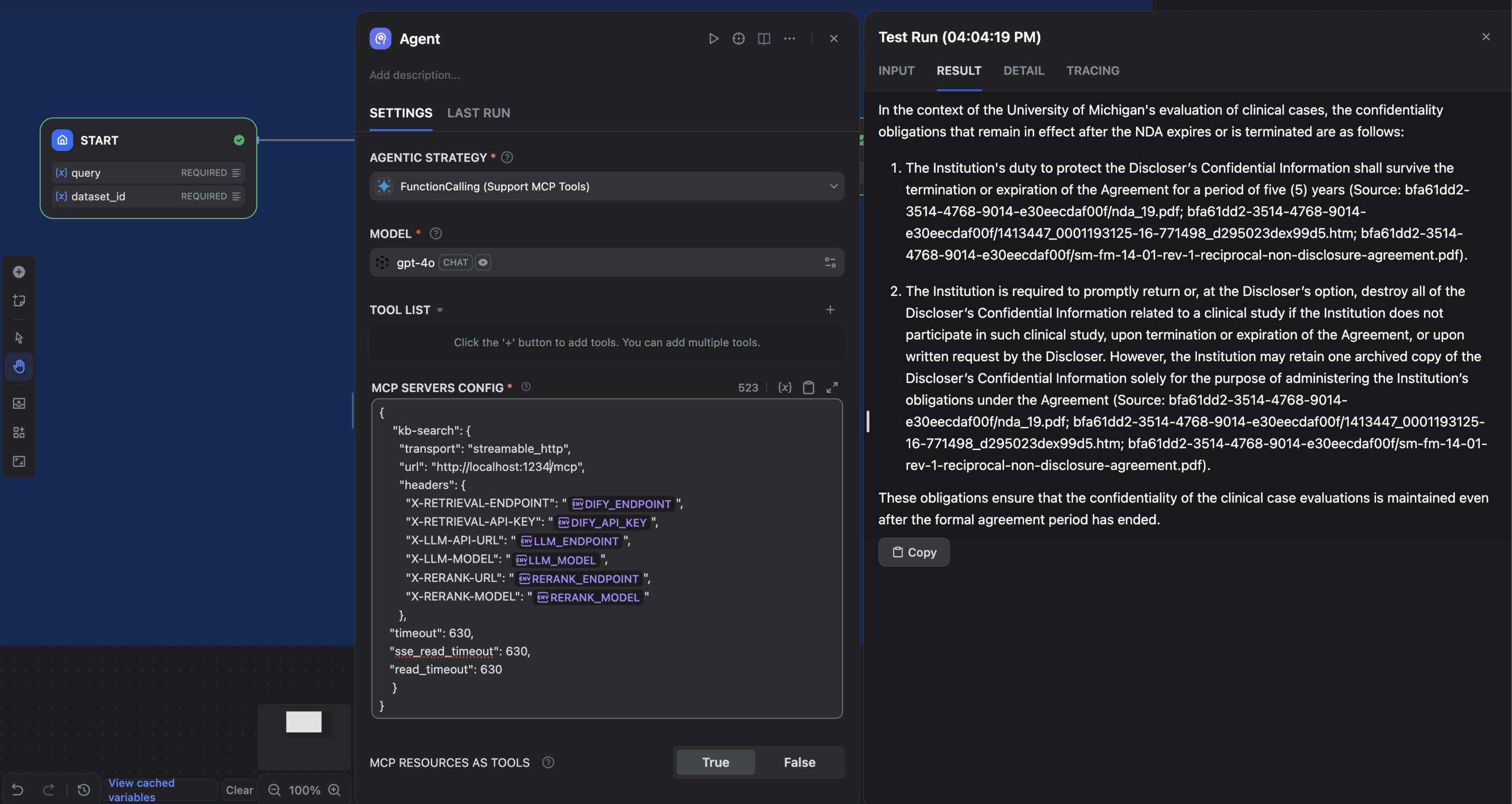
Under the hood
A few implementation details worth noting:
- File discovery uses semantic retrieval plus optional file-level reranking. Keyword generation (content booster) is not applied here; it’s saved for the per-file chunk search stage.
- Per-file multi-variant search runs the original query plus LLM-generated boosted queries in parallel across the top-k files.
- Reranking behavior is adaptive: comprehensive queries like “list all definitions” disable chunk reranking to avoid filtering out useful segments, and rerank queries are neutralized to reduce bias toward glossary sections.
- Answer extraction is intent-aware. Clause lookups preserve exact wording; multi-file comparisons emphasize alignment across entities and dates.
- Fallbacks: if the initial search yields nothing useful, the assistant tries a small set of neutral queries (e.g., “definitions”, “glossary”) before giving up.
- Reflection (optional) evaluates answer quality on grounding, completeness, consistency, and specificity, with a cap on refinement iterations.
Defaults: content booster is enabled with a small number of keywords per file, and reranking is applied at the file level when configured.
In the next post, I’ll evaluate performance and quality trade-offs on ContractNLI.