Funding Is Not Identity: A Conservative Approach to Onchain Entity Linking
Why Identifier Counts Are Not Entity Counts
Onchain systems love to count identifiers.
Wallet addresses. DIDs(decentralized identifiers). Governance voters. Delegates. Safes.
Those counts are useful, but they are not the same thing as entity counts. A single operator can control many wallets. A DAO team can manage multiple Safes. A bridge, exchange, or relayer can make unrelated addresses look connected.
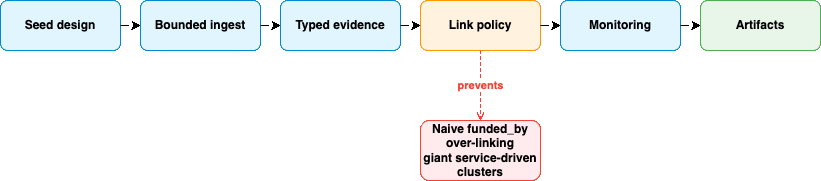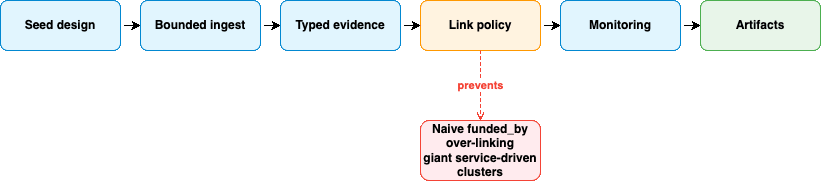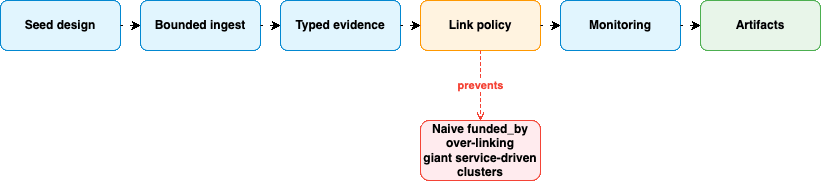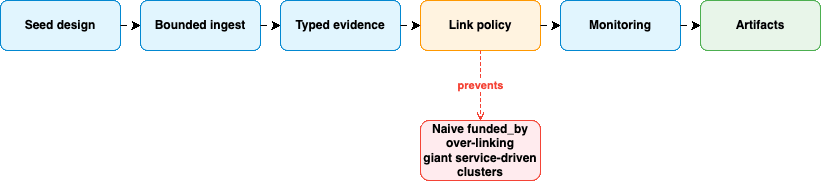
unmasking-did is not a deanonymization tool and it is not a Sybil detector. It is an evidence-preserving linker: every cluster must explain which signals connected the identifiers, and what those signals are allowed to mean. The point is to measure coordination without collapsing it into identity.
Evidence Before Identity
unmasking-did separates primary evidence kinds from derived coordination signals.
Primary evidence kinds are stored as typed rows and used directly by link policy:
| Primary evidence kind | What it can support | What it cannot prove |
|---|---|---|
funded_by |
relatedness / coordination candidate | identity or common control by itself |
safe_owner |
control-link candidate | same human or malicious behavior |
ens_handle |
self-declared identity claim | verified identity |
did_controller |
controller-style identity evidence | coordination behavior |
Derived coordination signals are computed at cluster or feature level — not stored as evidence rows:
| Derived signal | Typical use | Limitation |
|---|---|---|
| common sink concentration | consolidation-style behavior cue | not an attack objective |
| short funding burst | temporal coordination cue | not real-world identity |
It is easy for pipelines to blur these categories. A shared funder becomes evidence of common control; a DID becomes proof of identity. unmasking-did keeps the semantics separate: evidence type defines what a link means, while policy thresholds define how cautiously it can be used.
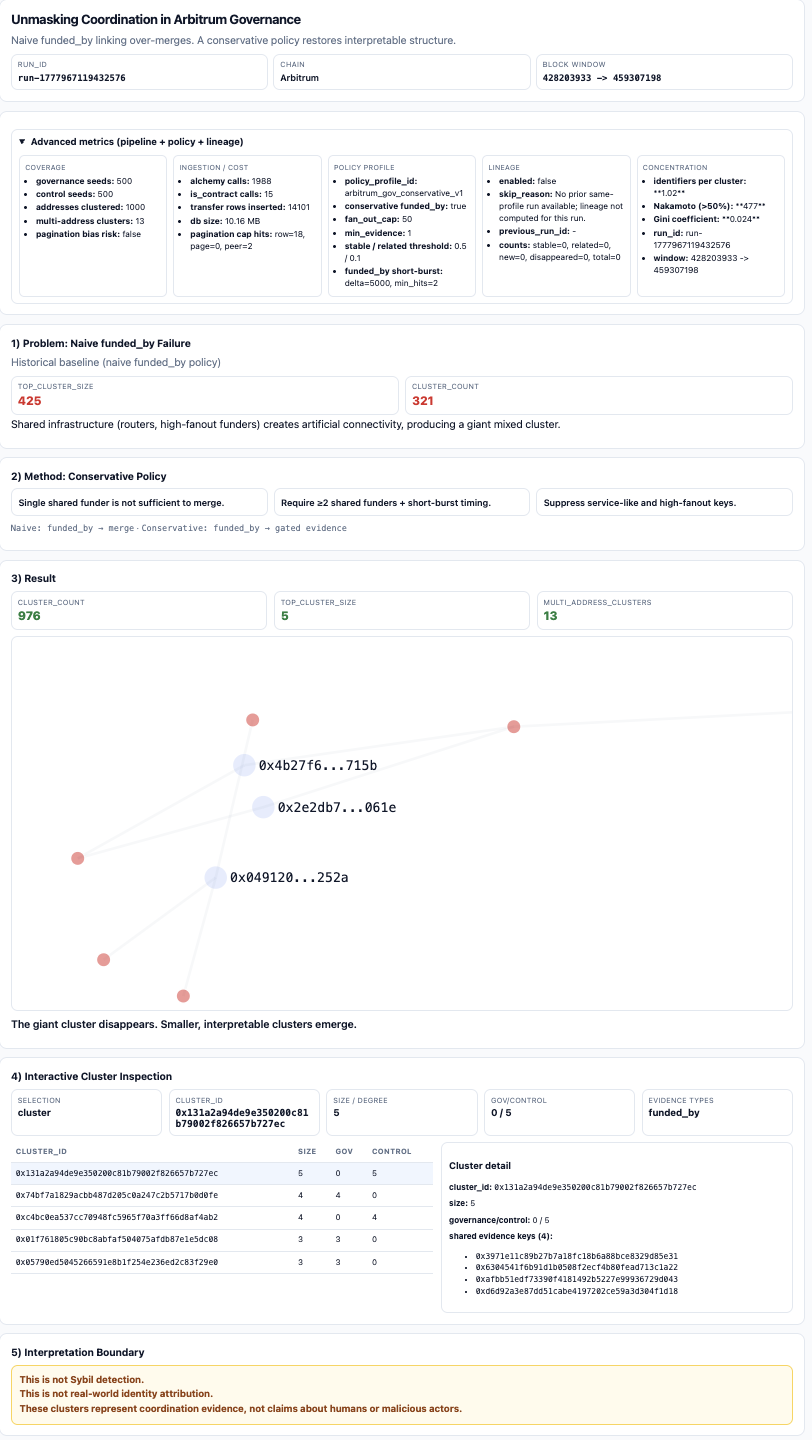
The Arbitrum Governance/Control Dataset
Before Arbitrum, I tested the pipeline on a small Scroll DAO Safe set: five governance Safes clustered through repeated Safe-owner evidence, while the Admin Multisig stayed separate. That was enough to validate control-style signals, but not enough to test funding-based coordination at scale.
Run specification and dataset details
Run ID: run-1777967119432576 - Chain: Arbitrum One
Monitoring window (frozen): block 428203933 → 459307198 (90-day scope)
Cohort design: 1,000 seed addresses total — 500 governance (stratified sample from VoteCast / VoteCastWithParams events), 500 control (ARB token transfer participants, same window)
Pipeline scope: predefined seeds only, no seed expansion; one-hop enrichment only, no recursive crawl.
Policy profile: arbitrum_gov_conservative_v1 — conservative funded_by enabled: min shared funders 2, min short-burst hits 2, short-burst block delta 5,000, service fan-out cap 50. Only runs under the same policy profile should be compared as trend-continuous results.
Full run specification: blog_run_spec_arbitrum_conservative_v0.md
Interpretation boundary: this dataset is built for coordination evidence analysis — not for Sybil detection claims, real-world identity attribution, or intent or maliciousness attribution.
The failure mode I wanted to test next was simple: would funding evidence accidentally turn a governance dataset into one giant entity?
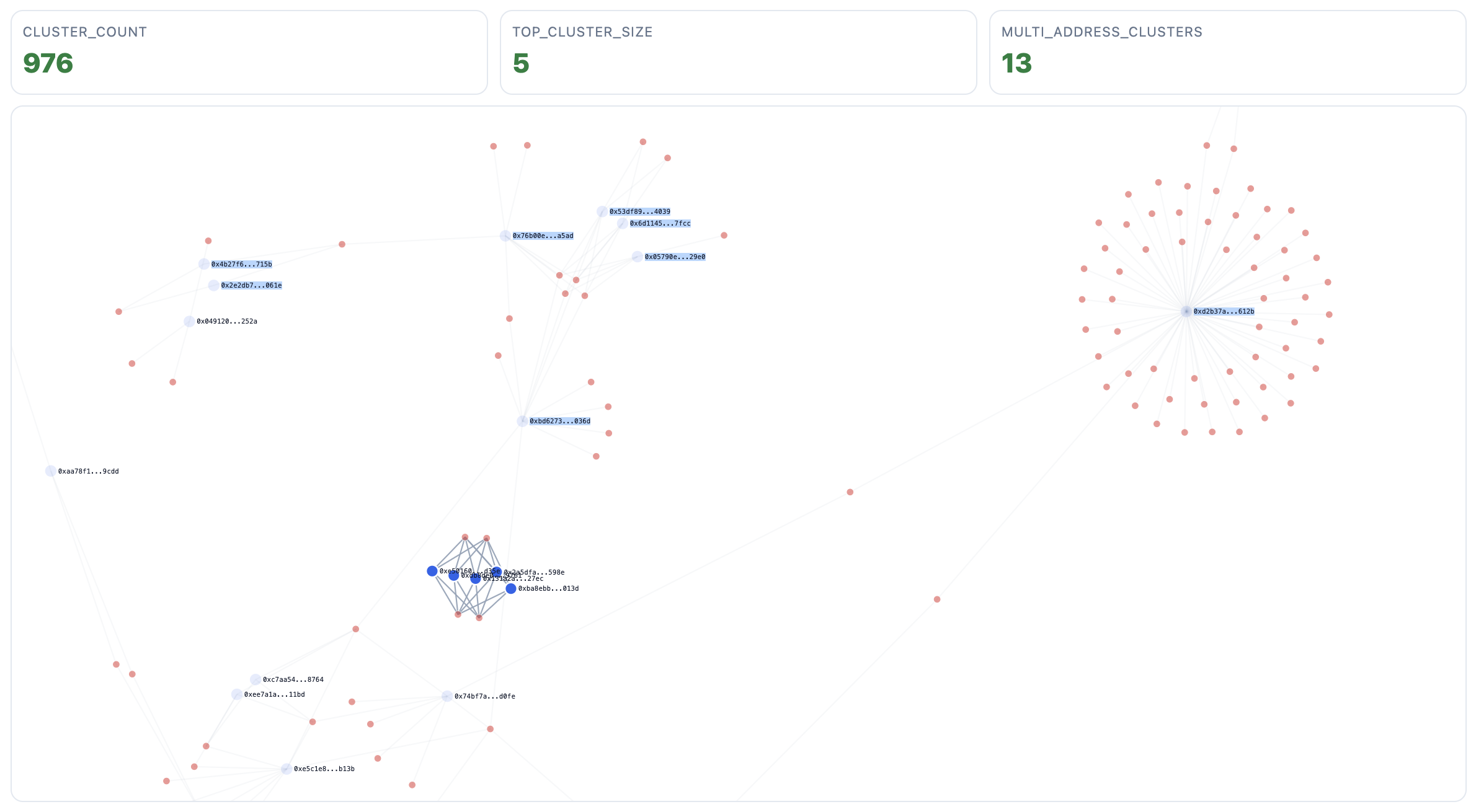
The Naive Failure: funded_by Creates a 425-Address Cluster
The original linker allowed funded_by to behave too much like merge evidence. That produced a giant mixed cluster:
| Metric | Original run |
|---|---|
| Cluster count | 321 |
| Top cluster size | 425 |
A 425-address component is visually persuasive. But if the glue is common infrastructure — service-like funders, routers, high-fanout sources — the component is not an interpretable entity cluster. It is infrastructure wearing the shape of identity.
Shared funding is not the same as shared control.
A single shared funder can support a “related candidate” label. It should not automatically merge addresses into a cluster.
Conservative Policy: Repeated + Short-Burst + Non-Service
The fix was not to remove funded_by. Funding still matters — it just needs to be demoted from naive identity evidence to conservative coordination evidence.
{
"funded_by_policy": {
"enabled": true,
"min_shared_keys": 2,
"min_short_burst_hits": 2,
"service_fan_out_cap": 50,
"short_burst_block_delta": 5000
},
"fan_out_cap": 50,
"min_evidence": 1
}
In plain English:
- one shared funder is not enough — require at least two shared
funded_bykeys - those links need at least two short-burst hits (block delta ≤ 5,000)
- service-like keys are suppressed — routers, bridges, zero/system addresses do not merge clusters
- high-fanout keys above the cap are treated as infrastructure
Timing is the key addition. Two addresses funded by the same source months apart are not the same signal as two addresses funded repeatedly in a tight block window.
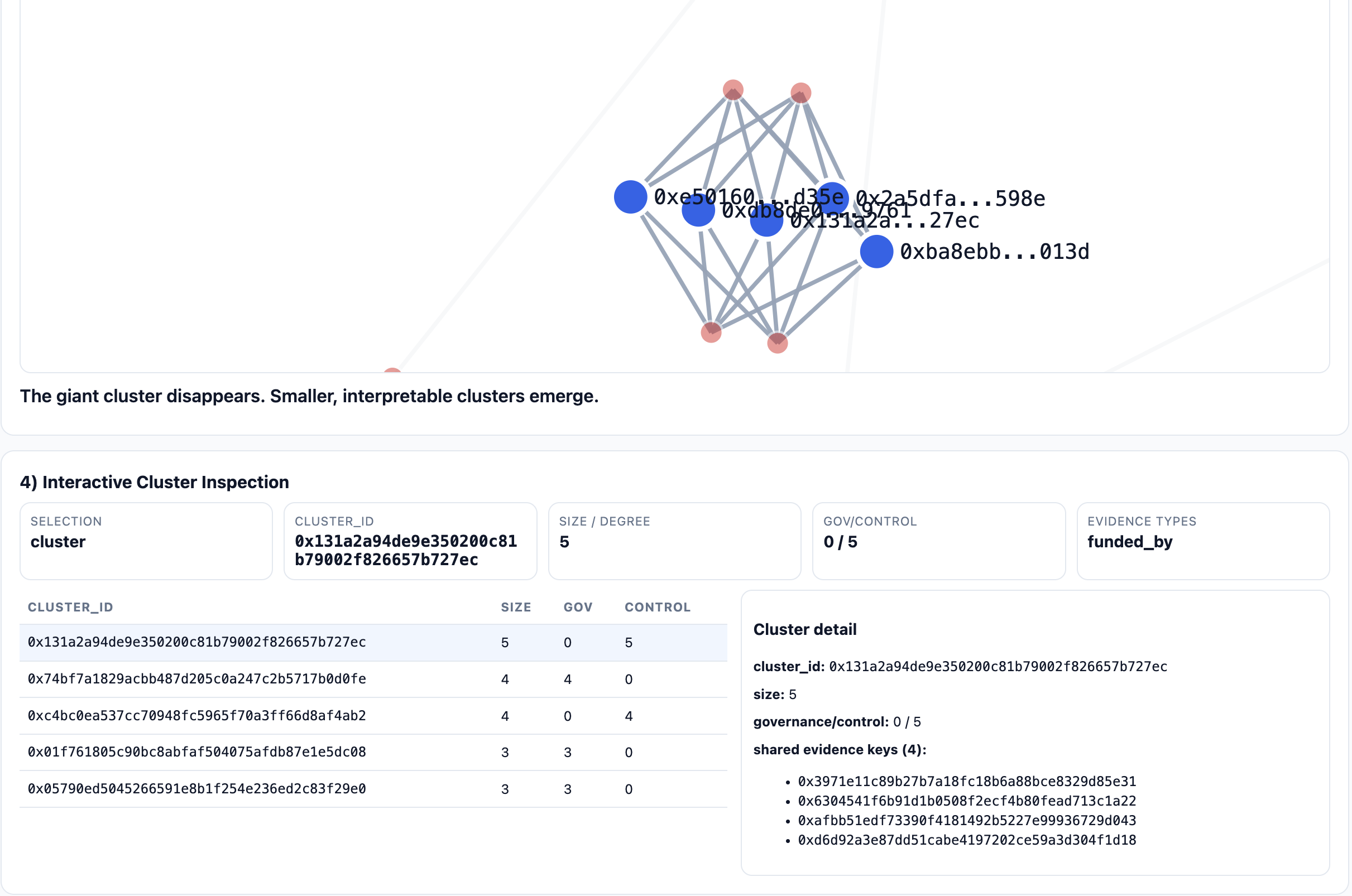
Result: Top Cluster 425 → 5
| Metric | Original run | Conservative run |
|---|---|---|
| Cluster count | 321 | 976 |
| Top cluster size | 425 | 5 |
| Multi-address clusters | many absorbed into one | 13 |
The top cluster went from 425 to 5. In this run, we observed no governance/control mixed clusters among the top clusters shown after conservative filtering. Treat this as a consistency check, not proof of absence: it reflects what survives the policy — including service and fan-out suppression — not everything that ever co-occurred in raw flows.
Two concentration metrics are worth calling out. The Gini coefficient is 0.024 and the Nakamoto coefficient is 477 (computed over inferred cluster sizes: the number of clusters needed to account for 50% of all clustered addresses). Both confirm the output is not secretly dominated by a few large components.
On the ingestion side, 1,988 Alchemy calls produced 14,101 transfer rows and a 10 MB SQLite database, with no db_size_stop trigger. The canonical summary, report, and bounded graph artifacts are in the repo under out/.

run-1777967119432576, policy profile arbitrum_gov_conservative_v1.
Why the Control Cohort Matters
Without a control group, every common funder can look suspicious. With one, the analysis can ask comparative questions under the same policy and window.
For the count rows below — short-burst clusters, high top-funder share, common-sink clusters, and candidate_* clusters — counts are computed over pure-by-cohort multi-address clusters only. Singleton clusters are included in the median cluster size and multi-address cluster-rate summaries.
| Metric | Governance | Control |
|---|---|---|
| Multi-address cluster rate | 3.0% | 4.4% |
| Median cluster size | 1.0 | 1.0 |
| Short-burst cluster count | 0 | 2 |
| Top funder share > 0.8 | 5 | 8 |
| Common sink cluster count | 0 | 0 |
| Review-priority medium clusters | 5 | 8 |
| Review-priority high clusters | 0 | 1 |
In this run, control is equal or higher across these coordination-oriented indicators. That does not prove governance is clean; it means governance does not appear elevated relative to this activity-matched baseline under the current conservative policy.
One caveat: the control cohort is ARB token transfer participants in the same block window — an activity-matched comparison, not a random sample of the full Arbitrum population. It controls for on-chain activity level, not for all behavioral differences. The baseline is useful; it is not a population ground truth.
Any claim that governance addresses behave unusually would need to clear this baseline first. The control cohort sets the floor, not the verdict.
The review-priority buckets only rank which clusters are worth reviewing first. They are not risk labels, misconduct labels, or claims emitted by the core linker.
The Viewer
For this project, the viewer is mostly an audit surface: it shows the evidence rows behind a cluster so I can tell whether a merge came from Safe ownership, shared funding, or a policy artifact. Cluster counts alone do not tell you that.
What This Is Not
This is not a Sybil detector. A real attack requires a target objective — airdrop farming, vote manipulation, reputation abuse — and this system does not observe objectives. What it produces is a cluster with a named evidence policy and an inspectable trail. Whether that cluster is interesting depends on context the pipeline does not have.
Next: From Snapshots to Monitoring
A single snapshot is easy to overfit.
For monitoring, the useful questions are whether clusters grow, split, disappear, or change funding patterns across windows.
The pipeline is designed for that shift. Each run has a fixed input snapshot, a frozen block window, and a policy profile that defines how evidence is interpreted. That makes runs comparable, not just reproducible.
The next useful version is boring on purpose: rerun the same policy every month, diff the clusters, and investigate only the changes that survive the same evidence rules.