Comparing Sequence-to-Sequence Decoders: With and Without Attention
This post goes beyond a conventional code walkthrough inspired by this tutorial. My goal is to elevate the narrative by offering a comprehensive comparison between Seq2Seq (sequence-to-sequence) models with and without attention.
Anticipate not only code insights but also a detailed exploration of the intricacies that position attention mechanisms as transformative elements in the landscape of sequence-to-sequence modeling.
Introduction
In this article, I guide you through the intricacies of NLP code implementation, emphasizing a structured and organized approach. We draw inspiration from a foundational tutorial to delve into the nuances of Seq2Seq models.
What sets this exploration apart is the comprehensive comparison between Seq2Seq models with and without attention mechanisms. While the original tutorial laid the groundwork, this article extends the narrative by evaluating and contrasting these models. Through this analysis, my goal is twofold: to provide a clear understanding of NLP implementation steps and offer insights into the structural organization of code components.
As we traverse Seq2Seq models, attention mechanisms, and code implementation, the intention is to enhance your understanding of NLP intricacies and showcase the meticulous approach applied to every code endeavor.
Let’s dive into the intricacies of Seq2Seq models.
Seq2Seq models play a pivotal role in machine translation, handling tasks like language translation. Consisting of an encoder and a decoder, these models process input sequences, create a semantic context, and generate an output sequence:
- Encoder processes input into a fixed-size context vector representing semantic meaning.
- Decoder takes the context vector and generates an output sequence, token by token.
In this exploration, we compare two decoder types within the Seq2Seq model: one with a basic Recurrent Neural Network (RNN) and another enhanced with an attention mechanism. The latter, Decoder-RNN-Attention, proves more complex yet often yields superior performance, especially for longer sequences.
Decoders
Decoders are fundamental components within Seq2Seq models, serving as the generative core responsible for translating encoded information into coherent output sequences. A decoder’s primary task involves taking a context vector, which captures the semantic essence of the input sequence, and meticulously generating an output sequence token by token. These tokens collectively compose the translated or transformed sequence. Decoders exhibit a spectrum of complexities and capabilities. Now, let’s explore the intricacies of both the basic RNN decoder, both with and without attention mechanisms.
Decoder-RNN
The Decoder-RNN, a fundamental RNN decoder, generates output sequences sequentially based on the encoder’s outputs and hidden states. Key attributes include:
- Generation Process: Outputs tokens one at a time, iteratively incorporating predicted tokens back into the model.
- Hidden State: Maintains a hidden state capturing context and information from the encoder, updated at each decoding step.
- Output: Lacks an attention mechanism, relying solely on the final hidden state for the entire input sequence context.
Decoder-RNN-Attention
Incorporating an attention mechanism, the Decoder-RNN-Attention significantly enhances its decoding prowess by selectively focusing on diverse segments of the input sequence. Key features include:
-
Attention Mechanism:: Leverages Bahdanau Attention (See Fig. 1) to dynamically focus on different encoder output segments during each decoding step.
- Context Vector:: Utilizes the attention mechanism to calculate a context vector, a weighted sum of the encoder’s output sequence. This context vector, combined with the previous token’s embedding, serves as input to the GRU cell.
- Generation Process: Similar to the Decoder-RNN, it produces the output sequence token by token. However, it incorporates the attention mechanism’s enhanced context, resulting in a more refined output.
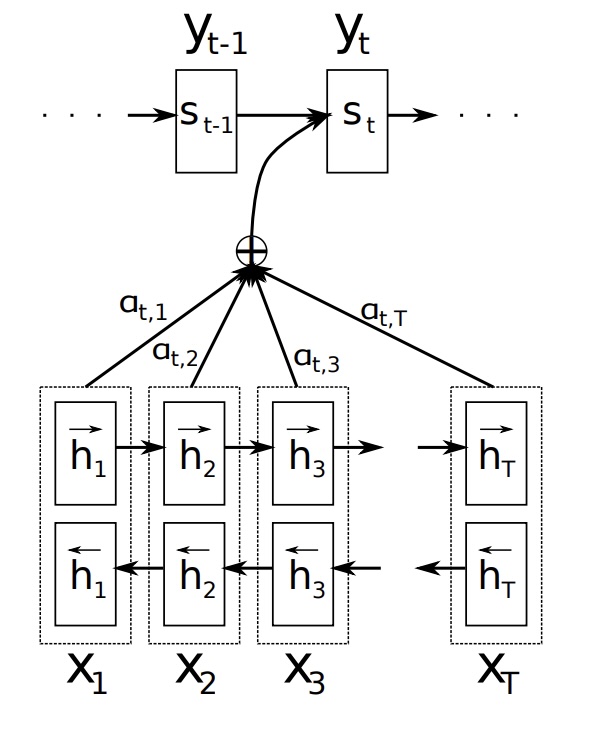
Comparison
- Complexity: The Decoder-RNN-Attention introduces increased complexity due to the attention mechanism, allowing dynamic focus on different parts of the input sequence.
- Performance: In practical applications, attention mechanisms often lead to superior performance, particularly evident when handling longer sequences. This improvement is showcased in the following results, emphasizing the attention mechanism’s ability to selectively attend to pertinent information, thereby enhancing translation quality.
The exploration of Seq2Seq models and their decoders lays a foundational understanding for the practical implementation that follows. Now, let’s dive into the intricacies of training these models and evaluating their performance in real-world translation tasks.
Practical Implementation: Seq2Seq Modeling
In this practical implementation, we meticulously structure and enhance the entire model training process, building upon tutorial.
I. Data Preparation
We utilize a dataset of English to French translation pairs from the open translation site Tatoeba, downloadable here in tab-separated format. The dataset is carefully trimmed to include only a few thousand words per language, managing the encoding vector’s size. The whole preprocessing is similar to tutorial.
Our data preparation implementation is encapsulated in the following classes:
LanguageDataClass- Manages language-specific data.
- Tokenizes sentences and maintains vocabulary.
DataReaderClass- Reads raw data, optionally reversing language pairs.
- Filters pairs based on specified prefixes.
PreprocessorClass- Orchestrates the data processing workflow.
- Enriches language data with sentences.
- Filters valid pairs.
II. Model Training Setup
Dataloader Classes
We’ve implemented custom dataloader classes based on training and testing datasets, featuring:
PairDatasetClass- Converts sentence pairs into tensor datasets.
- Prepares data for model consumption.
PairDataLoaderClass- Manages train and test dataloaders.
- Efficiently feeds batches into the model.
Model Architecture
The model architecture comprises:
EncoderRNNClass- Embedding layer captures context from input sequences.
- GRU layer encodes contextual information.
DecoderRNNClass- Unfolds sequence generation process.
- Produces translated sequences step by step.
AttentionDecoderRNNClass- Advanced decoder with attention mechanisms.
- Enhances model focus on relevant parts of the input sequence.
Explore the detailed implementation here.
III. Training Process
In the training process, our Seq2SeqTrainer class efficiently manages optimization using ADAM, cross-entropy loss calculation, and the training loop. It’s essential to note that this work simplifies the settings, with a focus on random dataset splitting for training and testing, rather than extensive hyperparameter tuning or early stopping.
Key hyperparameters are configured as follows:
- Parameters
batch_size = 256 hidden_size = 128 dropout_rate = 0.1 num_epochs = 500 training_rate = 0.8 learning_rate = 0.001
To initiate the training job, use the following CLI command:
- Command
python examples/translation/cli/seq2seq/run_model_evaluation.py --data_base_path examples/translation/data
Find the script with its arguments here.
Training Result
Explore the cross-entropy losses of both models across different epochs for a thorough understanding of their training performance.
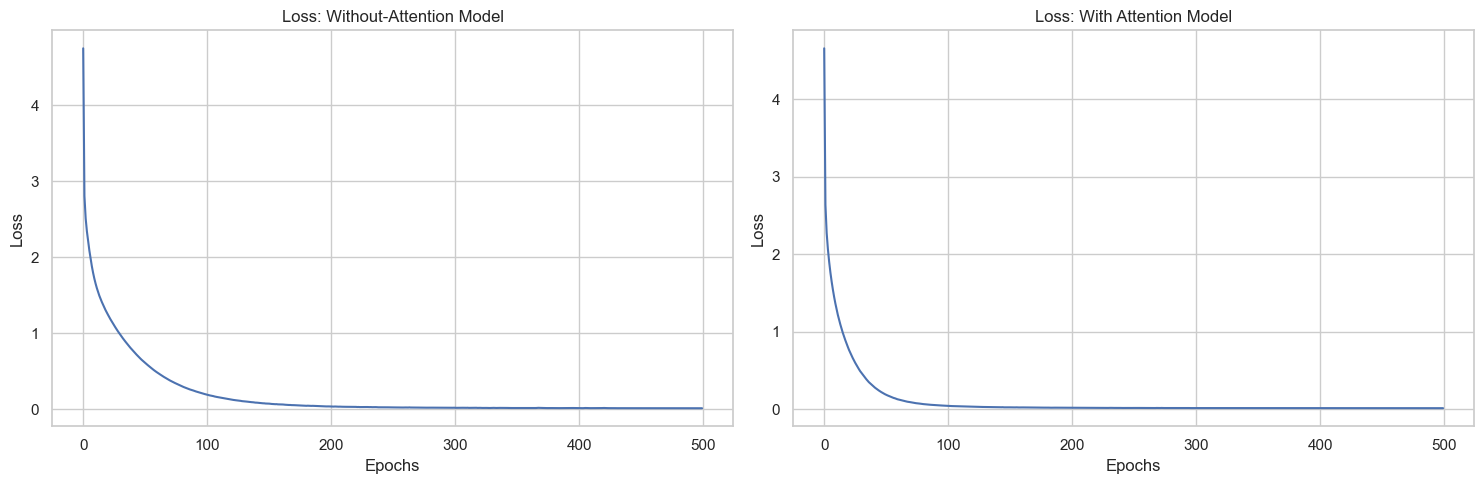
Fig. 2 shows that the losses of both models appear similar and converge, indicating comparable training dynamics.
IV. Inference
To assess the translation quality of the trained Seq2Seq models, we conduct a human evaluation by randomly selecting three sentences from the dataset. We utilize the Predictor class to showcase the capabilities of both models in translating these sentences.
- Example 1
>>> input_sentence, answer = random.choice(pairs) >>> LOGGER.info(f"Translate {input_sentence!r}") INFO:root:Translate 'je suis en train de me peser' >>> LOGGER.info(f"True: {answer!r}") INFO:root:True: 'i am weighing myself' >>> LOGGER.info(f"Result without attention: {' '.join(normal_predictor.translate(input_sentence))!r}") INFO:root:Result with attention: 'i am weighing myself' >>> LOGGER.info(f"Result with attention: {' '.join(attention_predictor.translate(input_sentence))!r}") - Example 2
>>> input_sentence, answer = random.choice(pairs) >>> LOGGER.info(f"Translate {input_sentence!r}") INFO:root:Translate 'vous etes bon cuisinier n est ce pas ?' >>> LOGGER.info(f"True: {answer!r}") INFO:root:True: 'you are a good cook aren t you ?' >>> LOGGER.info(f"Result without attention: {' '.join(normal_predictor.translate(input_sentence))!r}") INFO:root:Result without attention: 'you re kind of cute when you re mad' >>> LOGGER.info(f"Result with attention: {' '.join(attention_predictor.translate(input_sentence))!r}") INFO:root:Result with attention: 'you are a good cook aren t you ?' - Example 3
>>> input_sentence, answer = random.choice(pairs) >>> LOGGER.info(f"Translate {input_sentence!r}") INFO:root:Translate 'je suis plus petite que vous' >>> LOGGER.info(f"True: {answer!r}") INFO:root:True: 'i m shorter than you' >>> LOGGER.info(f"Result without attention: {' '.join(normal_predictor.translate(input_sentence))!r}") INFO:root:Result without attention: 'i m glad you re ok now' >>> LOGGER.info(f"Result with attention: {' '.join(attention_predictor.translate(input_sentence))!r}") INFO:root:Result with attention: 'i m shorter than you'
The results highlight a significant distinction: the “With Attention” decoder consistently provides accurate translations, aligning well with the true results. In contrast, the “Without Attention” decoder falls short in capturing the nuances of the translations, emphasizing the impact of the attention mechanism on improving translation accuracy.
V. Evaluation
This section provides a comprehensive evaluation by examining relevant metrics.
Metric Evaluation using the Test Dataset
To assess our models’ performance, we employ key metrics, providing unique insights into their capabilities:
-
Accuracy: Measures the exact match between the model’s predictions and the actual results, offering a straightforward measure of correctness.
-
ROUGE-1: Focused on unigrams, ROUGE-1 evaluates alignment between the model’s output and the reference text at the level of individual words. Precision, recall, and the F1 score within the ROUGE-1 framework offer distinct perspectives on the model’s effectiveness in capturing relevant information from the reference, particularly at the granularity of unigrams.
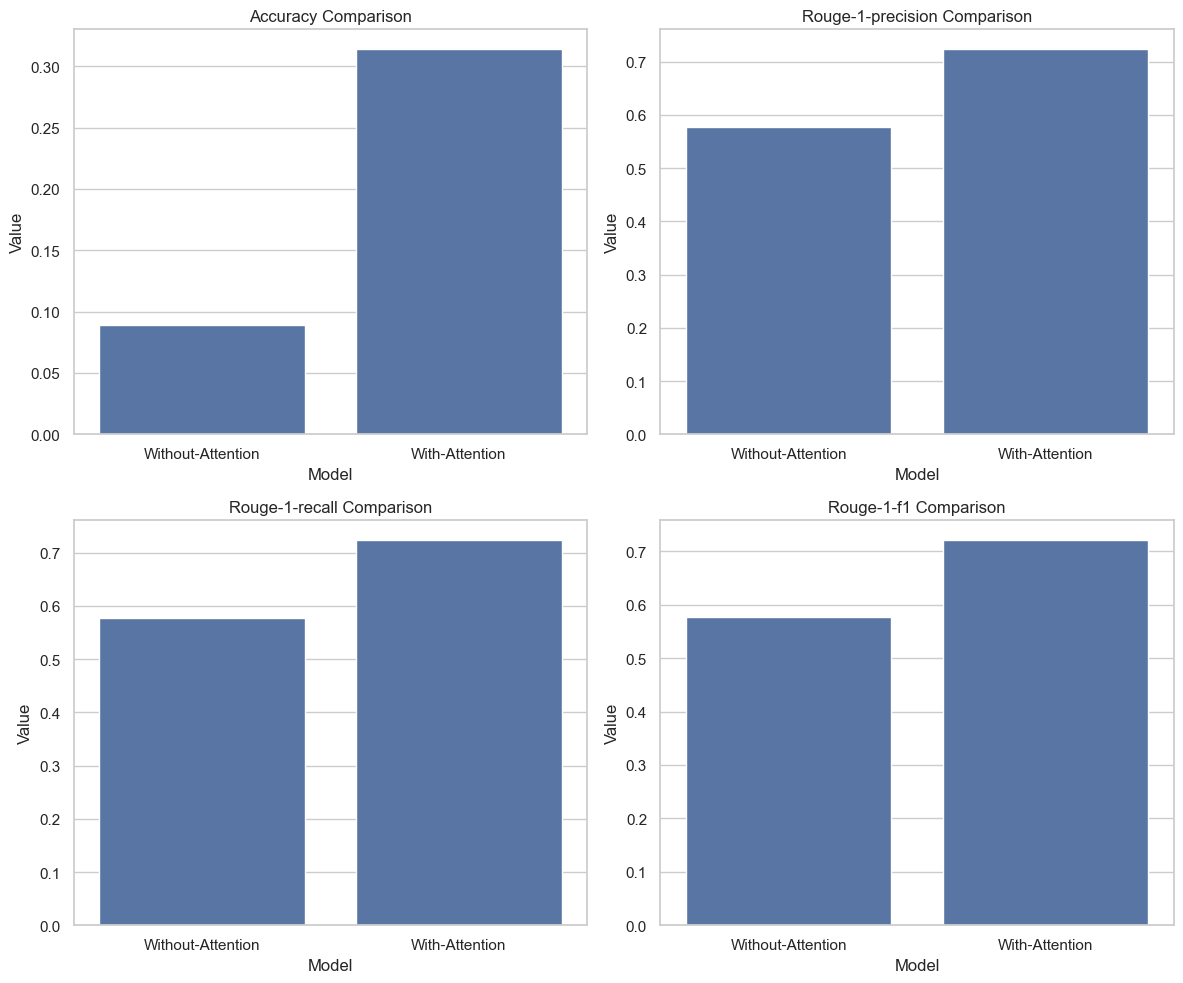
Fig. 3 illustrates that the “With Attention” decoder consistently outperforms the “Without Attention” decoder across all metrics—ROUGE-1 Precision, ROUGE-1 Recall, ROUGE-1 F1, and accuracy. This consistent superiority suggests that the attention mechanism significantly contributes to enhanced accuracy and improved text generation quality. The emphasis on individual words (ROUGE-1) reinforces the importance of attention in capturing precise details and nuances during translation.
To quantify these observations, we introduce an Evaluator class that systematically assesses the model’s performance using the specified metrics. The class takes the test dataset and a predictor as inputs and calculates accuracy, ROUGE-1 precision, recall, and F1 score. This comprehensive evaluation enhances our understanding of the models’ strengths and weaknesses.
Note that you can execute the notebook to reproduce the above results.
Summary and Acknowledgment
In conclusion, the Decoder-RNN-Attention, with its sophisticated attention mechanism, outperforms the basic Decoder-RNN, showcasing enhanced complexity and dynamic focus on input sequences. Its superiority is particularly evident when handling longer sequences, emphasizing the pivotal role of selective attention in machine translation. Despite both models converging in training losses, the ‘With Attention’ decoder consistently outperforms the ‘Without Attention’ decoder across diverse metrics, highlighting the critical significance of attention mechanisms.
These findings not only contribute insights into the nuanced performance of Seq2Seq models but also underscore the indispensable nature of attention mechanisms in shaping the future of Natural Language Processing. I encourage readers to explore the provided code and experiment with these models themselves.
Acknowledgment
I would like to express my gratitude to the authors and contributors of the tutorial on which this article is heavily based:
The insights and guidance provided in this tutorial laid the groundwork for the content presented here. This article extends the narrative by evaluating and contrasting sequence-to-sequence models with and without attention mechanisms, offering additional insights and practical implementation details.