Why ZK Rollups Need a Smarter Way to Manage State
Most ZK rollups still apply one demotion rule to every slot, whether it is a live token balance or a dead contract slot from years ago. Real access data does not support that assumption.
State growth is usually handled as storage engineering, not prediction. As state grows, sequencer lookup latency, witness-memory pressure, and node sync cost can all rise.
Fixed-threshold demotion is the wrong abstraction. A survival-model pipeline can convert censored slot-access histories into cost-aware tiering decisions, but the operating point depends on workload scale and cost calibration.
The key question is not which state is old, but which state is likely to be used again.
Fixed-Threshold Demotion Is the Wrong Model
The common approach is a fixed threshold:
\[d_i = \text{hot if last access gap} \le H,\ \text{cold otherwise.}\]This assumes all storage slots follow the same reuse pattern.
They do not.
A token balance, a dead contract slot, and a governance variable have different access dynamics. A single threshold H cannot represent all of them; this is misspecification, not parameter tuning.
Access Is Heterogeneous
The goal is not to identify which state is old. The goal is to estimate which state will be used again.
In both synthetic and real-trace runs, access is highly skewed: most slots are accessed once (or never again), a small subset dominates repeated accesses, and inter-access intervals are heavy-tailed. A uniform demotion rule assumes homogeneous behavior; the data does not support that assumption.
Statistical Formulation
Treat each slot i as a time-to-next-access random variable over inter-access intervals:
\[T_i = \text{time until next access},\quad X_i = \text{slot features.}\]The first version uses covariates observable from traces: contract identifiers, access frequency, recency, and same-contract co-access activity. More semantic features can be added later with verified metadata/code analysis.
For real-chain experiments in this post, the extractor is currently a Transfer-log surrogate rather than a full state-diff extractor: it captures pseudo balance-slot touches induced by Transfer events, but misses non-Transfer writes and all reads (see Caveats).
We want:
\[p_i(\tau) = \Pr(T_i \le \tau \mid X_i),\]the probability that slot i will be accessed within horizon $\tau$.
Observed data is censored and truncated:
\[(L_i, Y_i, \Delta_i, X_i),\quad Y_i = \min(T_i, C_i).\]Ignoring censoring biases reuse estimates downward. Ignoring truncation introduces survivorship bias. Both lead to incorrect $p_i(\tau)$ and therefore incorrect decisions.
Model
Use a Cox proportional hazards model:
\[\lambda(t \mid X_i) = \lambda_0(t)\cdot \exp(X_i^\top \beta),\]which yields:
\[p_i(\tau) = 1 - S_0(\tau)^{\exp(X_i^\top \beta)}.\]This yields per-slot reuse probability instead of a global threshold. PH may be violated in practice, but the decision layer needs calibrated $p_i(\tau)$, not literal model correctness. If ranking is adequate, held-out recalibration is often enough; if not, the survival model can be swapped without changing the decision rule.
Decision Rule
Let $d \in {\text{RAM}, \text{SSD}, \text{Cold}}$. Define $c(d)$ as storage cost and $\ell(d)$ as latency penalty if accessed. Expected cost:
\[\mathbb{E}[\mathrm{cost}_i(d)] = c(d) + \ell(d)\cdot p_i(\tau).\]Optimal placement:
\[d_i^* = \arg\min_d \left[c(d) + \ell(d)\cdot p_i(\tau)\right].\]This replaces a fixed rule with data-driven tiering. It is a slot-level surrogate for balancing hot-state footprint against fetch penalty, not a full proving-cost model.
Interpretation
This is not pruning. It is tiering.
High $p_i(\tau)$ → keep in RAM. Low $p_i(\tau)$ → move to cheaper storage. Correctness is unchanged. Only access latency changes.
Why This Matters
The bottleneck is not total state in the abstract, but the hot working set presented to the execution and witness/proving stack.
If reuse is sparse, most state does not need to stay hot. Reducing hot state can lower sequencer lookup latency and witness-memory pressure, improving throughput and lowering the node hardware bar without protocol changes.
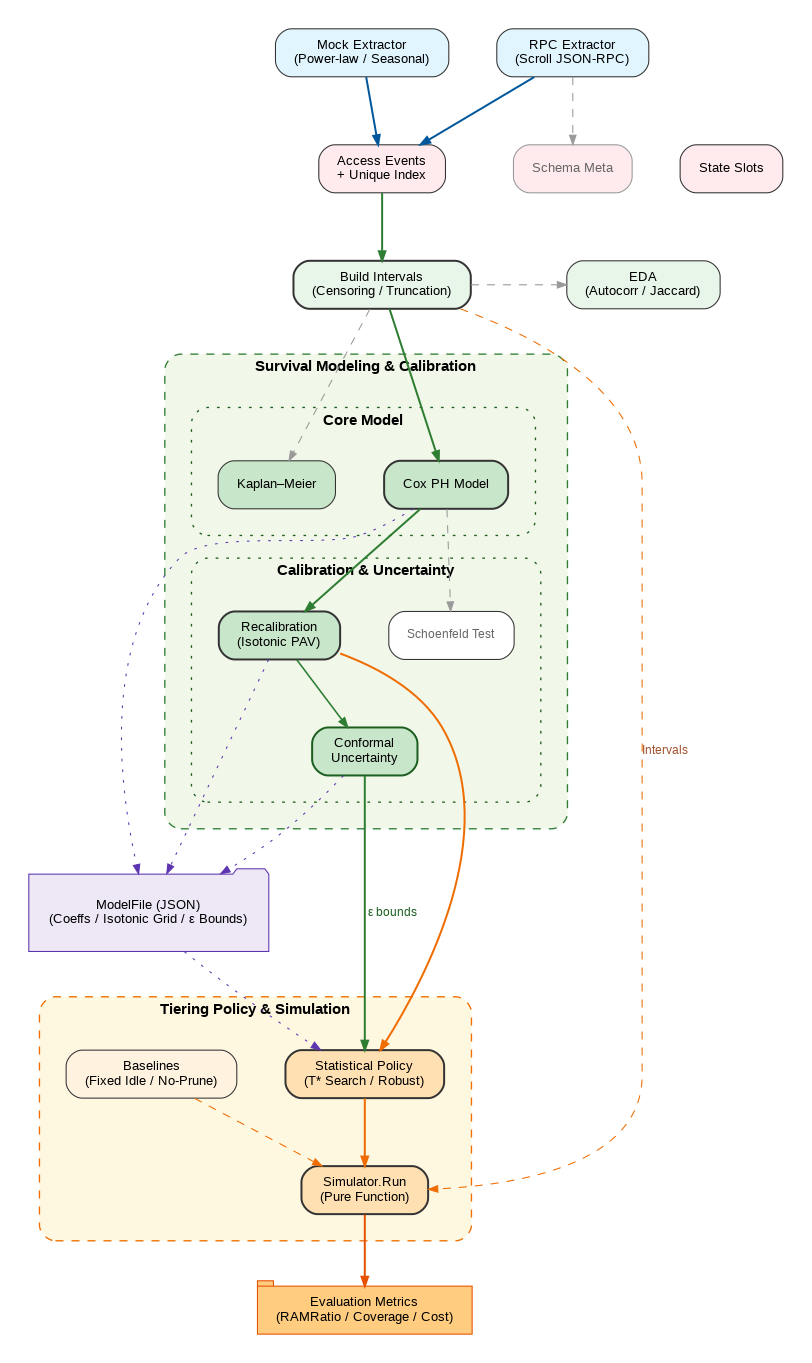
Evaluation
Compare against fixed-threshold baselines (H = 30d, 90d) and no-prune using four system metrics: RAM ratio, hot-hit coverage, miss penalty, and total cost. Calibration quality is measured on holdout Brier before/after isotonic recalibration.
The evaluation pipeline combines exploratory diagnostics, Kaplan-Meier baselines, Cox modeling with PH checks, held-out recalibration, conformal uncertainty estimation, and cost-aware simulation under fixed and statistical policies.
Early Evidence
Both synthetic and real-trace smoke runs support the core motivation: access is highly skewed and inter-access behavior is heavy-tailed.
The key finding is regime dependence. In the synthetic 160k-block window, statistical policy yields lower total cost across the 100-10,000 range and nears break-even around 100,000. In the Scroll smoke window ([33,414,002, 33,415,157), about 1,155 blocks), it yields lower total cost across the 1-100 range, then degrades from 1,000 and loses heavily from 10,000 upward. Cost calibration is tightly coupled to workload scale.
The high-$\ell$ failure mode is interpretable: as miss penalty grows, the statistical policy becomes increasingly conservative, keeps more slots hot, and eventually drifts toward a no-prune ceiling. In that regime, fixed windows that still demote can win on total cost.
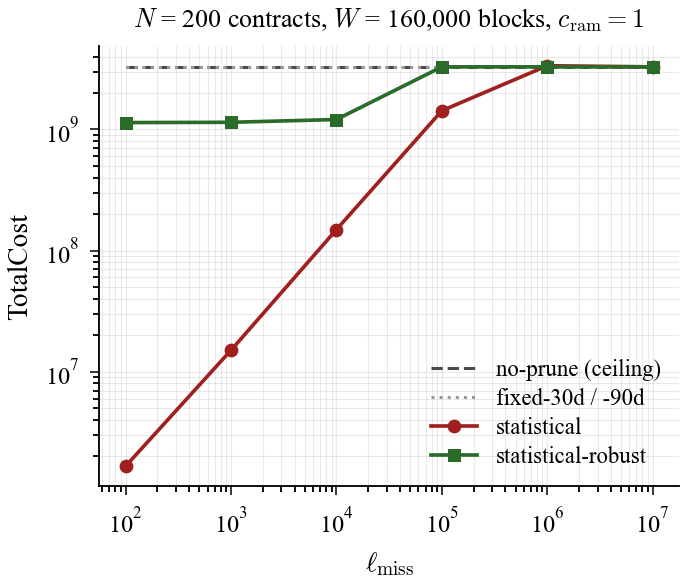 Figure 1a. Synthetic cost sweep: statistical policy dominates under moderate miss-penalty values and approaches break-even near high penalties.
Figure 1a. Synthetic cost sweep: statistical policy dominates under moderate miss-penalty values and approaches break-even near high penalties.
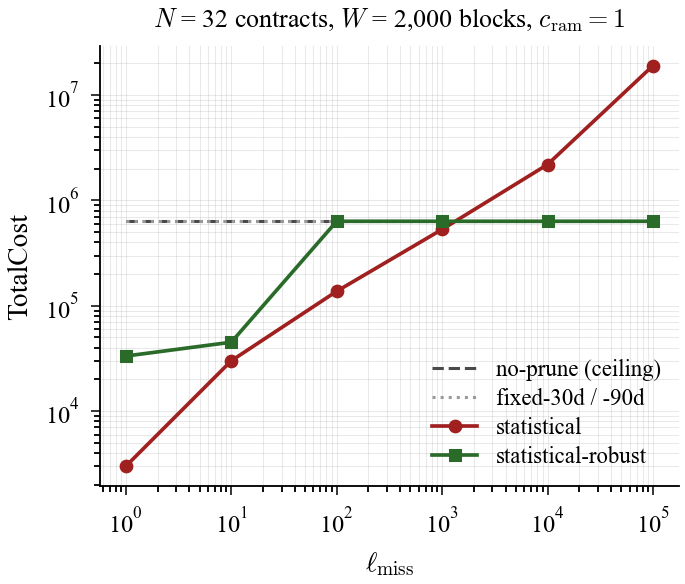 Figure 1b. Scroll smoke cost sweep: the winning regime shifts to much lower miss-penalty values, showing workload-scale sensitivity.
Figure 1b. Scroll smoke cost sweep: the winning regime shifts to much lower miss-penalty values, showing workload-scale sensitivity.
Calibration behavior also diverges. On synthetic data, isotonic slightly worsens Brier (0.171 → 0.175, +0.004). On Scroll smoke, isotonic improves Brier (0.223 → 0.197, about 12% relative). Isotonic is not uniformly beneficial: when raw Cox is already near-calibrated, recalibration may add little or slightly worsen Brier.
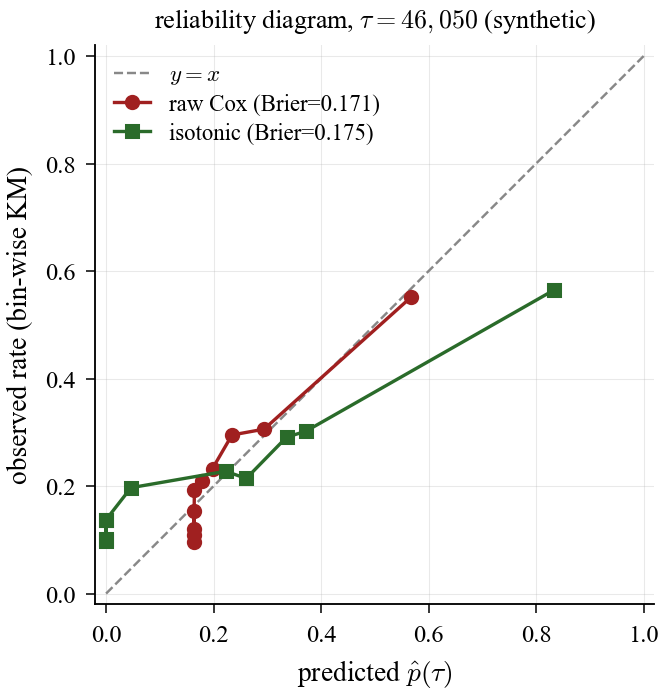 Figure 5a. Synthetic calibration: raw Cox is already close, and isotonic adds little in this regime.
Figure 5a. Synthetic calibration: raw Cox is already close, and isotonic adds little in this regime.
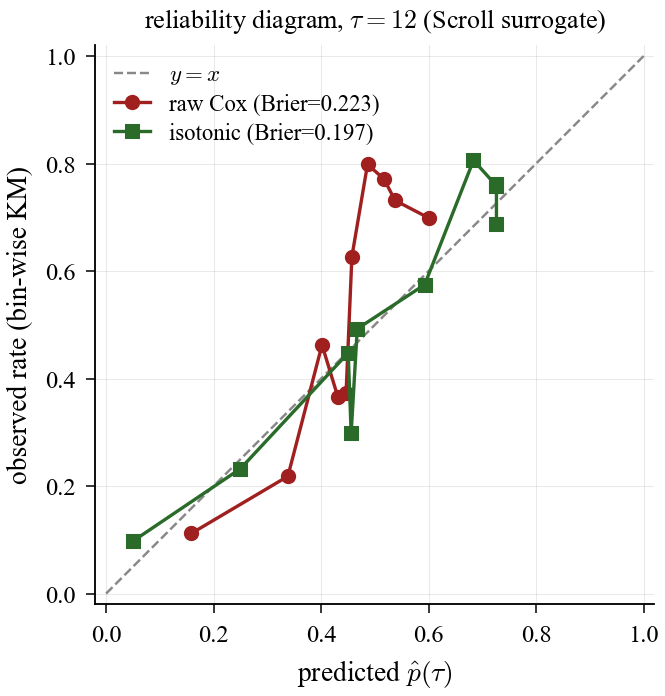 Figure 5b. Scroll calibration: isotonic correction materially improves calibration on the holdout split.
Figure 5b. Scroll calibration: isotonic correction materially improves calibration on the holdout split.
Heavy-tail diagnostics also diverge in magnitude: synthetic IAT Hill α = 1.26, while Scroll smoke gives frequency α = 1.10 and IAT α = 0.64, still indicating a heavier observed tail in the real-trace sample.
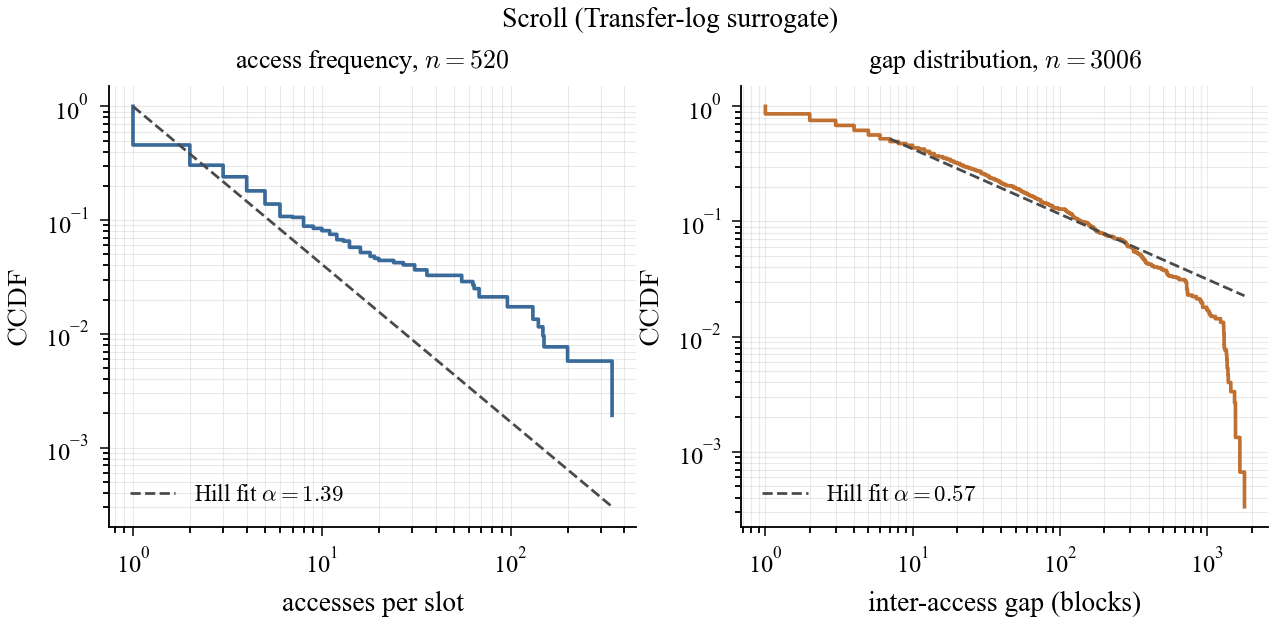 Scroll EDA (real smoke slice): access-frequency and inter-access distributions remain strongly skewed, with clear heavy-tail signatures.
Scroll EDA (real smoke slice): access-frequency and inter-access distributions remain strongly skewed, with clear heavy-tail signatures.
KM stratification on Scroll must be read with data-coverage limits: this run is ERC20-only (318 slots, 2,405 intervals), with no meaningful DEX/governance/bridge coverage. That directly motivates a Phase 4 state-diff extractor.
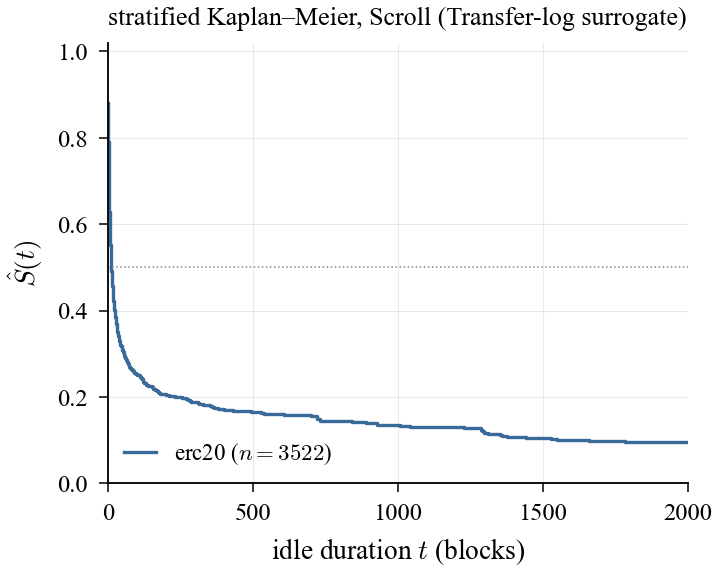 Figure 4b. Scroll KM view: survival structure is visible, but category coverage is narrow under the Transfer-log surrogate.
Figure 4b. Scroll KM view: survival structure is visible, but category coverage is narrow under the Transfer-log surrogate.
The table below is not a definitive benchmark; it is an early signal that framework behavior differs across synthetic and real traces, especially under miss-penalty miscalibration.
| Dataset | Heavy-tail signal (Hill α) | $\ell_\text{miss}$ range where statistical wins (units: $c_\text{ram}$) | Calibration (Brier raw → isotonic) | Notes |
|---|---|---|---|---|
| Synthetic smoke (160k window) | IAT α = 1.26 | ~100 to 10,000 (break-even near 100,000) | 0.171 → 0.175 (slightly worse) | Cox already near-calibrated in this setting |
| Scroll smoke (~1.2k-block window) | Freq α = 1.10, IAT α = 0.64 | ~1 to 100 (degrades from 1,000; large loss at 10,000+) | 0.223 → 0.197 (improves) | Stronger PH stress + tighter cost-ratio sensitivity |
To make the tradeoff more concrete, the table below reports the induced RAM ratio and hot-hit coverage for selected statistical operating points.
| Dataset | RAM ratio (%) | Hot-hit coverage (%) | Miss penalty | Total cost |
|---|---|---|---|---|
| Synthetic smoke (statistical policy, window [40k, 200k), $\ell=100{,}000$) | 0.07 | 7.27 | 1,427,100,000 | 1,429,318,925 |
| Scroll smoke (statistical policy, window [33,414,002, 33,415,157), default $\ell$) | 42.21 | 93.53 | 13,500,000 | 13,617,957 |
Current Implementation Status
Phase 3 adds persisted fitted models, category-stratified Cox baselines, explicit Schoenfeld checks, conditional conformal uncertainty, and a Scroll RPC Transfer-log surrogate extractor.
For a two-tier hot/cold setup, the decision rule reduces to a single probability cutoff, $p^* = (\mathrm{RAMUnitCost}\cdot \tau)/\mathrm{MissPenalty}$. The implementation also uses conditional survival $S(\mathrm{idle}+\tau)/S(\mathrm{idle})$ and transition-time search to avoid demoting too early within an interval. Unlike a fixed recency threshold, this cutoff is applied to predicted reuse probability rather than raw idle time.
Caveats
- Real-data extraction is currently a Transfer-log surrogate rather than a full state-diff extractor; non-Transfer writes and all reads are out of scope.
- Conformal $\varepsilon$ provides marginal rather than simultaneous coverage.
- Miss-penalty calibration is deployment-specific; if set too high, a statistical policy may underperform fixed baselines on total cost.
Summary
Fixed-threshold demotion rules assume homogeneous reuse. State access is heterogeneous and partially observed.
This is a survival analysis problem, not a threshold tuning problem.
State demotion should be driven by estimated future reuse, not by a single recency constant.
I’m building this as zk-state-prune, an open-source Go framework that fits Kaplan-Meier and Cox PH models to state-access traces, converts predictions to tiering decisions, and benchmarks against fixed-rule baselines.
This work is orthogonal to proposals like EIP-7928 (Block-Level Access Lists), but BAL-style traces are directly relevant to this project’s main blind spot: reads and non-Transfer writes that a Transfer-log surrogate cannot see.
The broader goal is to turn state management in ZK rollups from a fixed heuristic into a predictive systems problem.